.RU – версия 2.2
|
|||
| EXTRACTOR | .RU – версия 2.2 |
||
|
|
Что у нас есть? Это тоже интересно |
Статьи и описания форматов игровых файлов Как потрошить игровые архивыЭта статья относится к играм: Автор материала: Михаил Бесчетнов aka Terminus В статье, в качестве примера, описывается процесс распаковки архива формата DAT из игры Imperium Galactica II Предположим, что вам захотелось добыть графику из некой игрушки. Предположим также, что ваш выбор пал на Imperium Galactica II. Те же правила подойдут практически к любой игре.
Начнем с поиска самих ресурсов. В принципе, видов хранения информации в играх немерено. Однако вначале следует взглянуть, не лежат ли спрайты/картинки/звуки в привычном для нас формате (bmp,jpg,wav и пр.). Если вы нашли что-то подобное, значит вам крупно повезло. Если нет — можете продолжать читать дальше.
Разные производители по разному и ресурсы прячут. В одном случае можно найти текстуры, размещенные по отдельным файлам, в другом их запаковывают в архивы, точнее — в псевдоархивы, т.к. в них довольно редко применяются алгоритны сжатия и в полном смысле этого слова архивами они не являются. Значит, ищем файлы, которые выделяются своим размером на фоне остальных. Впрочем, архивы могут быть и сравнительно небольшими, как в нашем случае с IG2. Здесь в каждом архиве содержится иногда по одному, а иногда и по сотне файлов. Вот этот случай мы и рассмотрим. При расшифровке любого формата вероятность успешного результата резко возрастает, если разбирать одновременно несколько образцов этого формата. В нашем случае используется два архива: sounds_colony_speech_self-destruct.dat и textures_colony_lens.dat.
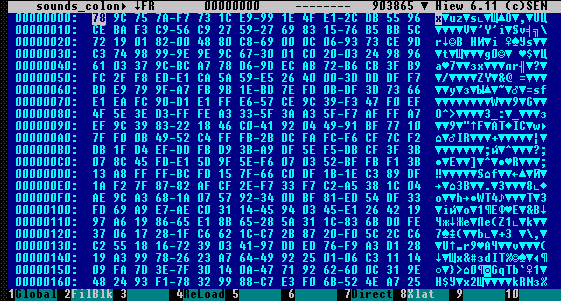
Итак, подопытные архивы отобраны. Теперь пришла пора найти содержащиеся в них файлы. В каждом архиве есть область, в которой описываются все файлы. Назовем эту область FAT (File Allocation Table). В каждом же архиве имеется и заголовок (Header), в котором может раполагаться смещение до FAT, идентификатор формата, количество файлов, Copyright и много еще чего. Как правило Header располагается в начале архива, реже — в конце, очень редко — его нет совсем, однако это уже тяжелый случай. Для начала попробуем найти FAT в одном из наших архивов. Зрительно он определяется довольно просто — это область, где группы байтов располагаются с некой переодичностью. Проще всего это увидеть , если сравнить с . В первом случае данные располагаются хаотично, и регулярность не улавливается. Кроме того, FAT отличается обилием нулей в своих полях, особенно в начале. Объясняется это тем, что смещение первых (а иногда и всех) файлов ограничивается значением 16’777’215 (или даже 65’536) т.е. помещается в трех (или двух) из четырех байт значения типа LongInt и один(или два) байт остается нулевым. Это очень заметно. Ничего этого в начале нашего первого архива нет. Так что искать там нечего.
Рисунок 1
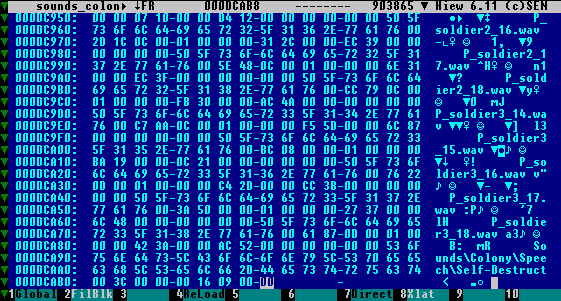
Перейдем в конец нашего архива и к рисунку 2. Сразу бросаются в глаза имена файлов. Ну вот, найден FAT. Его расшифровка теперь — дело техники. Теперь надо найти информацию о смещении FAT и об общем количестве файлов. Ищем глазами начало FAT (на рисунке он за пределами видимости). Обнаруживаем, что начинается он по смещению $DC1A3. Но ведь нашей задачей стоит не разбор конкретного архива, а возможность с помощью отработаного метода разобрать любой архив DAT. Так что ищем универсальный способ определения адреса FAT. Адрес этот может отсчитываться как от начала, так от конца архива. Получаем два адреса: от начала — $DC1A3, от конца — $DCAB9(размер архива)-$DC1A3=$916. Попытаемся найти любой из этих адресов в конце архива. И находим значение $16 09 00 00 по адресу $DCAB5. Это последние 4 байта архива.
Рисунок 2
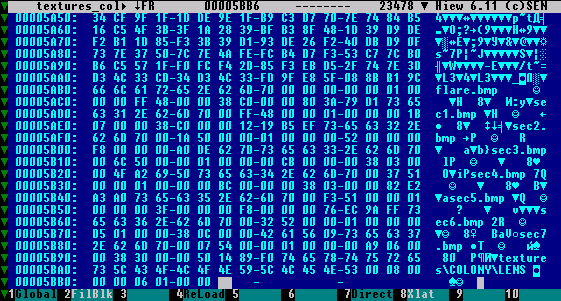
Теперь обратимся ко второму эксперементальному архиву и к . Как мы уже поняли, предположительно смещение FAT можно прочитать в последних четырех байтах архива. Чтобы окончательно подтвердить это предположение, посмотрим на последние четыре байта второго архива (). Там, по смещению $5BB2 читаем значение $106. Вычитаем это значение из общего размера архива и получаем $5AB0. Идем по этому смещению и куда попадаем? Да, на начало FAT второго архива. Значит, гипотеза подтвердилась.
Рисунок 3
Осталось только рассмотреть структуру записи об одном из файлов. Вот содержащиеся в записи поля (в скобках указана длина поля):
Длина поля имени может быть во всех записях фиксированой или произвольной. Во втором случае либо перед полем указывается длина имени, либо (как в нашем случае) имя читается до первого нулевого символа. Остальные поля отгадываются эксперементально. Размер первого файла=Смещение второго-смещение первого. Само смещение можно отгадать. Это особенно легко, в случае если все файлы имеют один и тот-же тип, т.е. имеют общий идентификатор в заголовке. Например, во втором архиве рассмотрим запись о первом файле (смещение $5AB0), и о втором (смещение $5ACE). После имени первого файла, пропустив один нулевой символ, читаем $00 00 00 00. Будем считать, что это и есть смещение до первого файла. Идем по этому смещению, т.е. в начало архива и запоминаем хотя бы два первых байта — $78 9C. Теперь читаем те же четыре символа — $FF 48 00 00. Идем по этому смещению ($48FF) и видим те же два байта. Т.о. совпадают идентификаторы обоих файлов, следовательно поле, содержащее смещение файла определено верно. Таким же методом научного тыка определяются и остальные поля.
Напоследок хотелось бы уделить внимание еще кое чему. Иногда файлы в псевдоархивах сжаты совершенно настоящим архиватором GZip. Этот метод использован и в IG2, и в HOM&M III. Идентификатором формата GZip является последовательность $1F 8B 08 00 00 00 00 00 00 00. Однако в играх этот идентификатор по неизвестной мне причине заменяют на $78 9C. Что бы при распаковке псевдоархива сформировать полноценный архив GZip из того файла, что там хранится, например, правильно извлечь из второго архива файл flare.bmp (), нужно:
Вот, собственно, и все. Надеюсь, эта статья что-то для вас прояснила. На самом деле, сколько типов архивов, столько и методов их распаковки, так что все варианты сразу описать невозможно.
Примечание от 11 ноября 2001г. Маневр с «ложным заголовком» GZip справедлив в том, и только в том случае, когда вы используете библиотеку GZipLib или другие библиотеки того же класса. При использовании ZLib заголовок редактировать не надо. |
| © | 2000—2010 «EXTRACTOR.ru» — игровые ресурсы: распаковка музыки и графики, конверторы форматов и многое другое… |